What is Zookeeper
ZooKeeper is a high-performance coordination service for distributed applications. It exposes common services - such as naming, configuration management, synchronization, and group services - in a simple interface so you don’t have to write them from scratch. You can use it off-the-shelf to implement consensus, group management, leader election, and presence protocols.
Zookeeper提供了如下的一致性保证:
- 顺序一致性。客户端的更新顺序与它们被发送的顺序相一致。
- 原子性。更新操作要么成功要么失败,不会更新半拉。
- 单系统镜像。无论客户端连接到哪一个服务器,客户端将看到相同的 ZooKeeper 视图。
- 可靠性。一旦一个更新操作被应用,那么在客户端再次更新它之前,它的值将不会改变。
- 实时性。在特定的一段时间内,客户端能够得到数据变化的通知
Name Space
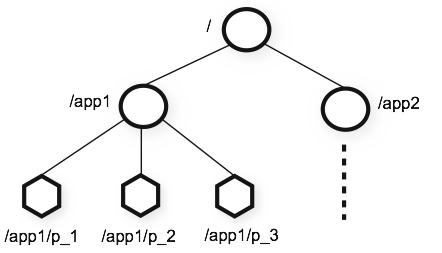
如图所示,zookeeper的命令空间是一个树状结构,类似于文件系统。树中的每个节点对应一个znode。
Znode
- znode通过路径来唯一标识
- znode有分为PERSISTENT和EPHEMERAL(EPHEMERAL的生命周期依赖于client session,对应session close/expire后其znode也会消失)
- znode的数据读写是原子的
- znode的数据数据结构
- czxid : The zxid of the change that caused this znode to be created.
- mzxid : The zxid of the change that last modified this znode.
- ctime : The time in milliseconds from epoch when this znode was created.
- mtime : The time in milliseconds from epoch when this znode was last modified.
- version : The number of changes to the data of this znode.
- cversion : The number of changes to the children of this znode.
- aversion : The number of changes to the ACL of this znode.
- ephemeralOwner : The session id of the owner of this znode if the znode is an ephemeral node. If it is not an ephemeral node, it will be zero.
- dataLength : The length of the data field of this znode.
- numChildren : The number of children of this znode.
- zonde的数据大小是有限制的,默认最大是1M,可以通过修改环境变量jute.maxbuffer来设置
Zookeeper Cluster
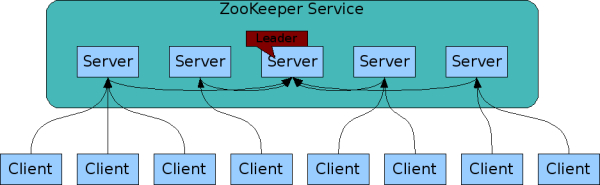
Zookeeper中的每个节点都在内存中有个一份所有数据的副本。
角色
Zookeeper集群中,每个节点担任下面的一种角色。
- leader:集群的管理者(数据同步,数据更新提议),通过paxos算法选举出来的
- follower:参与投票,在leader出问题时,可以被选举为follower
- observer:定时从leader同步数据,提高系统的读性能
Paxos
Paxos是一种分布式一致性算法,是zookeeper保证数据一致性的基础。网上关于paxos的内容还挺多的,有兴趣的自行找吧。
Zookeeoer的应用
- Leader Election
- Group Membership
- Configuration Management
- Cluster Management
- 分布式锁
- 分布式队列
实践
Zookeeper自身提供的接口比较麻烦,网上有很多开源的zookeeper client的封装实现,目前用了netflix出的curator,这里examples有一些例子,有兴趣的可以看下。
参考资料
- http://zookeeper.apache.org/
- http://rdc.taobao.com/team/jm/archives/2318
- http://zookeeper.apache.org/doc/r3.4.4/zookeeperAdmin.html
- http://www.searchtb.com/2011/01/zookeeper-research.html
- http://en.wikipedia.org/wiki/Paxos_algorithm
- http://rdc.taobao.com/team/jm/archives/448
- http://rdc.taobao.com/blog/cs/?p=162
- http://agapple.iteye.com/blog/1292473
- http://rdc.taobao.com/team/jm/archives/665
- http://rdc.taobao.com/team/jm/archives/947
- http://rdc.taobao.com/team/jm/archives/1070
- http://rdc.taobao.com/team/jm/archives/1232
- http://rdc.taobao.com/team/jm/archives/1241
- http://rdc.taobao.com/team/jm/archives/1384
- http://www.spnguru.com/2010/08/zookeeper%E5%85%A8%E8%A7%A3%E6%9E%90%E2%80%94%E2%80%94paxos%E7%9A%84%E7%81%B5%E9%AD%82/
- http://blog.csdn.net/shenlan211314/article/details/6187040
